

Introduction
The Internet Movie Database (IMDb) is a website that serves as an online database of world cinema. This website contains a large number of public data on films such as the title of the film, the year of release of the film, the genre of the film, the audience, the rating of critics, the duration of the film, the summary of the film, actors, directors and much more. Faced with the large amount of data available on this site, I thought that it would be interesting to analyze the film data on the IMDb website between the year 2000 and the year 2017.
=> Python code is available on my GitHub and in this link as well.
Comparison between Python and R
To do my analysis on the data from the IMDb website, I hesitated between Python and R. Since I used both for different personal projects, I can thus compare them. Here are my personal observations on these languages for Data Science:
- The R language is a language whose syntax is quite simple, it is very simple to use and manipulate vectors and matrices with R from a dataset, and then display the graphs. This is clearly an oriented language for data analysis and by practicing with R, I found that this language has a wide variety of advanced graphics, especially with the ggplot2 library. The R language also already has statistical functions and offers many packages to deal with a specific problem of Data Science. So I’m not surprised that R is very used by statisticians. The R language is a language that reminds me of the MATLAB language to make scripts in order to deal with engineering problems, and I often used vectors and matrices with this language to draw graphs, and also to interact with Simulink models (modeling of robotic systems, Kalman filters, UAVs for vertical flight, etc.). So I am sure it should be possible to do Data Science with MATLAB as well, even though this language is more focused on mathematics and engineering (industry, robotics, mechatronics and computer vision).
- Python is a programming language wider than R. It is an Object-Oriented Programming language (OOP) and it is also a scripting language. With Python, it is possible to develop graphical user interfaces, software applications, network (client-server, TCP, sockets), games, create a 3D model with a Python script in Blender, create a website, and of course data analysis (Data Science). It may be just an anecdote, but YouTube (the video hosting website) bought by Google, is developed in Python. So it is possible to make a lot more with Python than R. Python is also a language that obeys logic of indentation, it is very suitable for quickly implementing complex algorithms and it is scalable, that is to say it is able to process a large volume of data and is more efficient in data processing time than R.
Therefore, I preferred to use Python to analyze the IMDb website data.
Python and Data Science
To do Data Science with Python, I use Python with the following software libraries:
- Numpy: it contains many functions for numerical computation (vectors, matrices, polynomials, etc.).
- Matplotlib: it allows to trace and visualize data in the form of graphs.
- Pandas: it allows to manipulate and analyze data (dataframes).
- Seaborn: it complements Matplotlib by providing attractive statistical graphics.
There is also the Python Scikit-learn library that allows machine learning, but I did not need it for this data analysis on IMDb.
The first task of the Data Scientist is to prepare the data, this step may take a long time if the data is not available as a CSV file. Then, after the dataset is ready, the Data Scientist must explore the data and analyze it. Once this step is done, he must model the data, adapt and validate it. During this phase, it is possible to use machine learning techniques to predict the information you want. As I said before, in this study of IMDb, I did not need to use machine learning because I do not try to predict from data on IMDb. Once the data modeling is complete, the last step is to visualize the results and interpret them.
In fact, the purpose of Data Scientist is primarily to make the data talk, to make sense of the data from a large volume of structured or unstructured data, collected or scattered, internal or external, to bring out the useful information that will bring added value in for example a business in order to increase the turnover of a company.
Study of the problem
Objective: Analyze the data available on the IMDb website for movies released in the cinema between 2000 and 2017.
Preparing the dataset
On the IMDb website, it is possible to filter the searches, and thus to display all the movies for one year, such as the year 2017. For example, the first page of all 2017 IMDb movies is available under the following URL:
http://www.imdb.com/search/title?release_date=2017&sort=num_votes,desc&page=1
So I started to list all the data available on this page, understand their meaning, and especially think of a way that can recover the data on IMDb. After having inventoried the data available on this page and understanding the meaning of each data item, I started the data selection phase, that is, the data I want to keep for my Data Science study.
Here are the data I want to keep:
- Movie title
- Genre of the film
- Duration of the film (in minutes)
- Release year of the film
- Number of public votes
- Public rating (score out of 10)
- Critics rating (score out of 100)
- Movie Gross (millions of dollars)
It remains now to recover these data on all the films between 2000 and 2017. My knowledge of HTML, CSS and Javascript helped me a lot to find a way to recover this data automatically. Like any website, the IMDb site code is HTML, CSS and Javascript. It was therefore necessary to parse this HTML code, and to recover only the concerned data between certain HTML tags and to apply this on several pages and on all the years of the year 2000 to the year 2017.
So I developed a Python script using the BeautifulSoup library, which allows to parse HTML code, I limited the parsing to 8 pages for each year, so starting with the year 2000, my Python script retrieves the data on 8 pages, then redo the same step on the following year until the year 2017. It is a webscraping technique.
In my Python script, I send a GET HTML request to the IMDb site to retrieve the concerned page at regular times. Before launching the Python script, I still looked at the IMDb website with the movie list, and I realized that some data is missing on this IMDb site. For some movies, there is for example, no gross, no votes or no duration of the film. Since there are a lot of movies, it is likely that there are other missing data, so if I had started my Python script, I would have got a dataset with missing values.
I have been thinking of several solutions to fix this dataset problem with missing values as follows:
- Delete the line with the missing values
- Fill empty fields with specific values
- Fill empty fields with calculations
I opted for the first solution, so I updated my Python script, so that it does not take into account the movies whose data is missing during the parsing. Once done, I run my script, and waited half an hour to recover the data between 2000 and 2017.
Data analysis
I thus recovered the dataset with the Python script. With the Pandas library, it is possible to have an overview of the dataset and by applying functions like info(), describe() and head(), I could check the contents of my dataset.
With the head() function applied to my dataset, I display a part of the dataset. I have displayed the first 8 data as below:
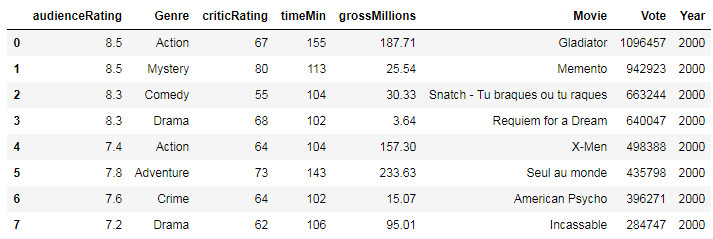
We find the selected data:
- Movie title -> Movie
- Genre of the movie -> Genre
- Movie duration (in minutes) -> timeMin
- Release year of the film -> Year
- Number of public votes -> Vote
- Public rating (score out of 10) -> audienceRating
- Critics rating (score out of 100) -> criticRating
- Movie Gross (in millions of dollars) -> grossMillions
Then I apply the info() function on my dataset:
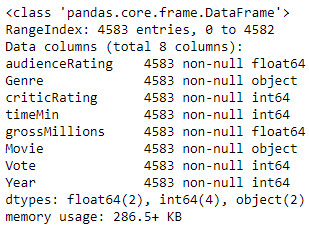
We can see on the image above, that I recovered 4583 entries (lines) with 8 columns (one type of data for each column). For each column of data (audienceRating, Genre, etc.), I do not have any missing values (non-null) and the typing of the data seems consistent, for example, I have a float for the public note ( audienceRating), an integer for the year and the number of votes. However, the Genre and Movie columns are by definition strings and Python interprets them as object type. To be able to use and visualize these two data Genre and Movie, I have to type them in category and I get:
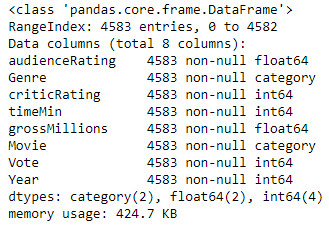
The two data Genre and Movie are therefore category type.
Then, I display the statistical summary of the dataset with describe().
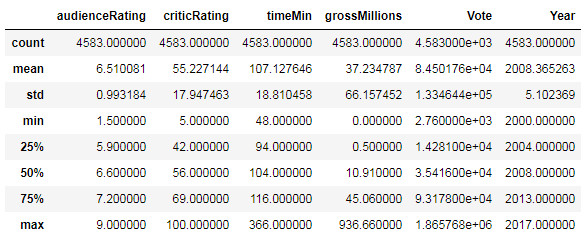
With this summary, I have access to a lot of information about my dataset, such as number of rows, average data, standard deviation, minimum, maximum, and all three quartiles.
Statistical modeling of data
As said before, I selected the following data for the statistical modeling:
- Movie title -> Movie
- Genre of the movie -> Genre
- Movie duration (in minutes) -> timeMin
- Release year of the film -> Year
- Number of public votes -> Vote
- Public rating (score out of 10) -> audienceRating
- Critics rating (score out of 100) -> criticRating
- Movie Gross (in millions of dollars) -> grossMillions
From this data, I can trace all kinds of graphics that the Pandas library allows.
Visualization of data and interpretation of data
I can visualize audience ratings (audienceRating) based on critics ratings on all movies released between 2000 and 2017.
Graphical representation of audience ratings based on critics ratings between 2000 and 2017:
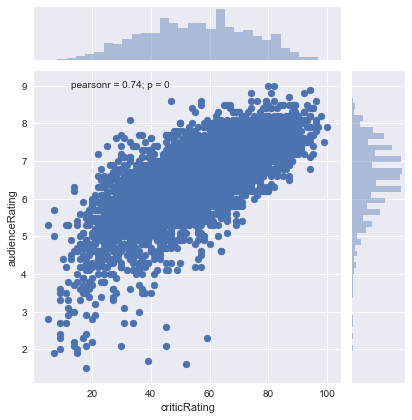
We see that there is a high concentration of points, following a straight line, which means that in most cases, the audience ratings of the movies are in agreement with those of the critics ratings. We also see that for the public, the distribution is stronger between 5/10 and 8/10 and those of the critics between 30/100 and 80/100, which confirms that in most cases, the coherence between the audience ratings and critics ratings.
However, we can see that for some movies, the public is not in agreement with the critics, for example, for some movies, the audience ratings are between 1/10 and 3/10 while the ratings of the critics are between 40/100 and 60/100. We can also see that for other films, the audience ratings (ratings of the public) are between 4/10 and 7/10 while those of the critics are between 20/100 and 50/100.
In this graph, we can conclude that the public often appreciates the movies and generally gives a score above 5/10 while the critics are more severe because the ratings of the critics are often lower than those of the public for any movie.
Hexagon representation of audience ratings based on critics ratings between 2000 and 2017:
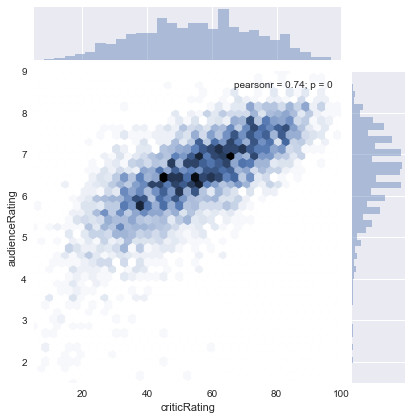
On this graph, we can see the linearity of the notes between the audience and the critics.
The most popular movies by the public and critics between 2000 and 2017
After searching the dataset, we can determine the most popular movies by the public and the critics. The best movies appreciated by the public between 2000 and 2017 are:
- “The Century of the Self” released in 2002 with a score of 9/10.
- “The Dark Knight: The Black Knight” released in 2008 with a score of 9/10.
The movie most appreciated by the critics is:
- “Boyhood” released in 2014 with a score of 100/100.
Graphical representation of audience ratings by length of film between 2000 and 2017:
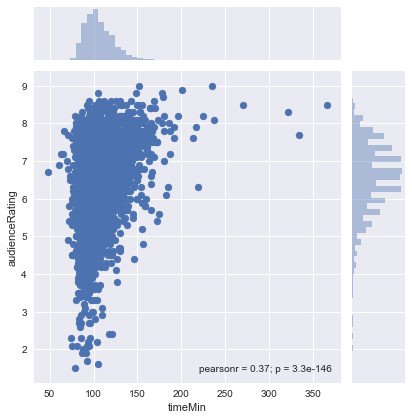
On this graph, we see that most of the movies last between 60 minutes and 120 minutes and collect the most scores and these scores are between 4/10 and 8/10 with a majority of scores above 6/10.
For some films that last more than 3 hours (180 minutes), we notice that the public appreciates them because it generally gives a score above 7/10. In this graph, we see that the longest film lasts 366 minutes, ie 6 hours and 10 minutes and has a score of 8.5/10, and after a search in the dataset, it is about the film “Our best years” released in 2003 which is a drama film.
Graphical representation of the ratings of the critics according to the duration of the film between 2000 and 2017:
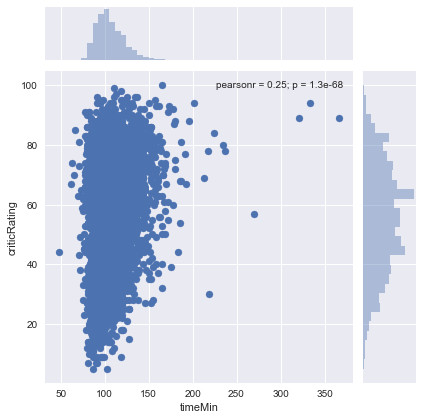
On this graph, we note that for films between 60 minutes and 120 minutes, the ratings of the critics are more concentrated and vary between 10/100 and 98/100.
Graphical representation of the gross of the films according to the notes of the public between 2000 and 2017:
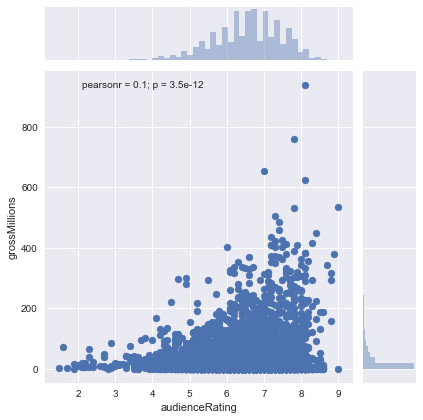
On this chart, it is clear that the movies that have been well rated by the public are movies that have generated the most millions of dollars, which is logical because if people have enjoyed a movie, they will talk about them, which will encourage other people to go to the cinema to see it, and thus increase the gross of the movie. Audience (public) ratings are more concentrated between 5/10 and 8/10.
In the dataset, the movie that brought in the most millions of dollars is the movie “Star Wars: Episode VII – The Force Awakens” with 936.66 million dollars released in 2015.
Graphic representation of the gross of the films according to the scores of the critics between 2000 and 2017:
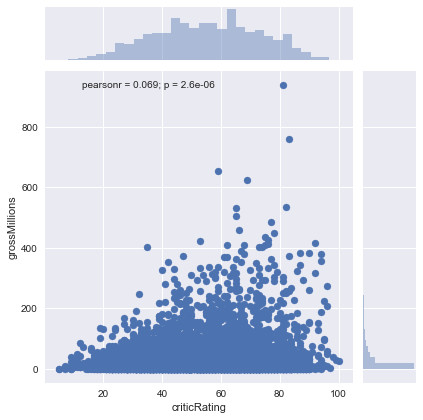
In this graph, we note that the ratings of the critics are more concentrated between 30/100 and 80/100, which means that the critics are more demanding towards the films than the public. We also note that the films that have high ratings from critics are those who have brought back a lot of money.
Graphical representation of the number of votes according to the scores of the public between 2000 and 2017:
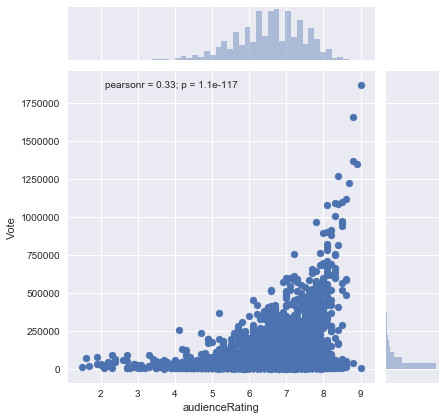
On this graph, we can see that the more people enjoy a movie, the more they vote and give a good rating.
The film that garnered the most votes is the movie “The Dark Knight: The Dark Knight” with 1865768 votes.
Graphic representation of the gross of the films according to the duration of the film between 2000 and 2017:
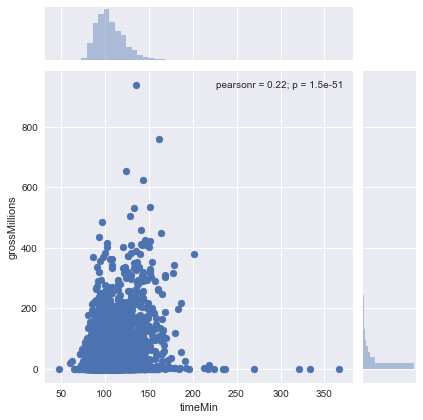
On this graph, we notice that the movies between 60 minutes and 150 minutes (2h30) are the ones that bring the most. On the other hand, movies with a very long duration, exceeding 3 hours, yield much less, that is to say, under one million dollars.
We deduce that a director should avoid making a film with a duration at least 3 hours, and that he should limit his movie to duration between 1 and 2:30 so that his audience does not get tired during the projection of the film.
Distribution by audience, critics, duration, gross, votes and year:
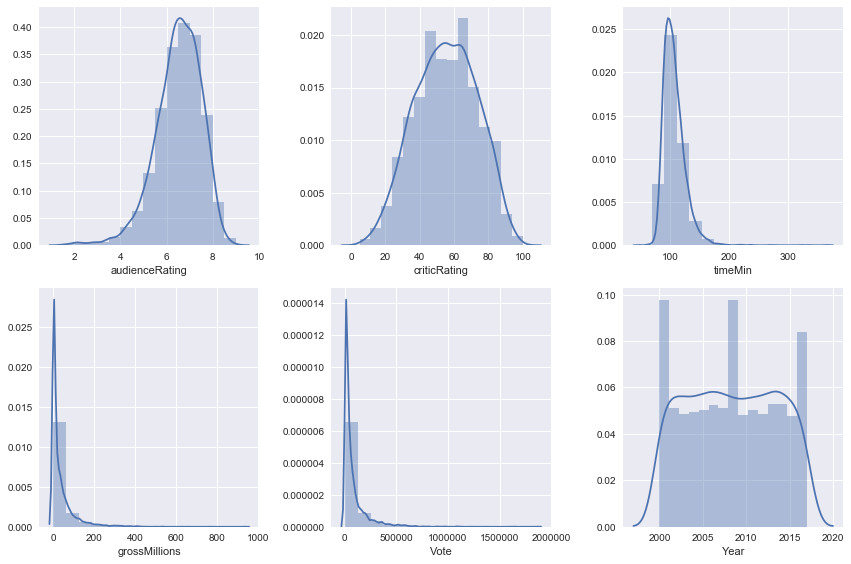
- Audience Ratings: Most of the audience ratings are between 6/10 and 7/10.
- Critics Ratings: Most critics ratings are between 40/100 and 70/100.
- Duration of the movie: a large number of films have a duration of 100 minutes (1h40).
- Movie Gross: Most movies are worth between $ 0 and $ 100 million.
- Number of votes: Most votes are between 0 and 250000 votes.
- Year: Many movies were released in 2000, 2009 and 2017.
Histograms of movies by genre between 2000 and 2017
Faced with the large amount of data, I divided my dataset into 3 sub dataset by grouping by 6 genres for each dataset because I had 18 genres of films on my whole dataset.
The genres of movies are:
- Action
- Adventure
- Animation
- Biography
- Comedy
- Crime
- Documentary
- Drama
- Family
- Fancy
- Horror
- Music
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
I thus obtain three graphs of histograms by group of 6 genres.
Histogram of the gross by genre of movie between 2000 and 2017:
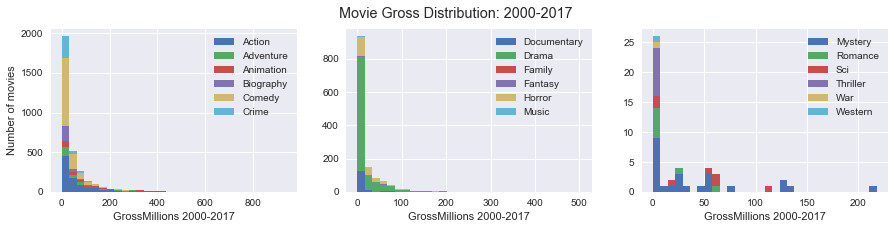
On this histogram, we see that the movies of biography, comedy, crime, drama and horror were the most numerous between 2000 and 2017. There were few mystery, western or war movies during this period.
We also note that the films that brought in the most (between 200 and 400 million dollars) are action, drama, and mystery movies.
Histogram of audience ratings by genre of movie between 2000 and 2017:
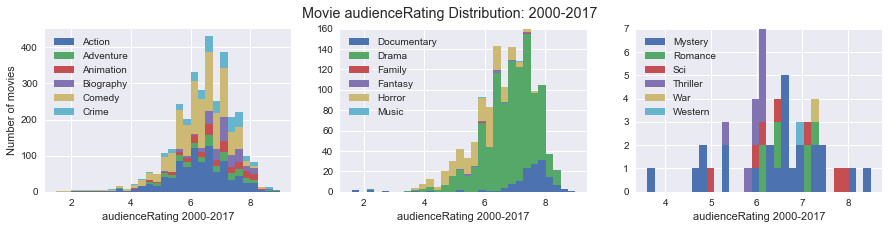
We note that the action, adventure, animation, biography, comedy, crime, documentary, drama, mystery and science-fiction movies were the most appreciated by the audience (score superior or equal at 8/10).
Histogram of the critics ratings by genre of movie between 2000 and 2017:
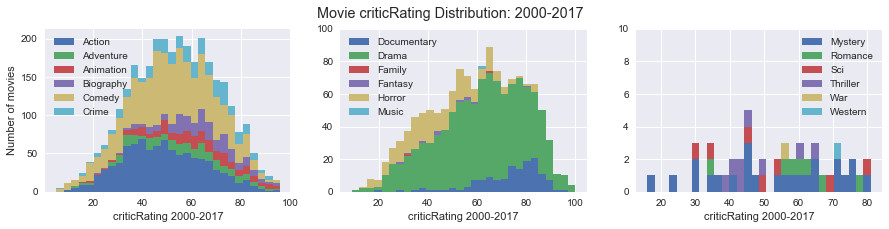
We note that adventure, animation, biography, comedy, documentary, drama, science fiction and mystery films are the top rated films by critics (score greater than or equal to 80/100).
Histogram of votes by genre of movie between 2000 and 2017:
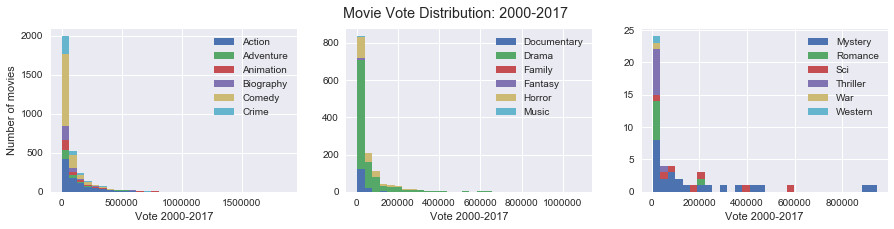
Animation, drama and mystery films received the most votes compared to other films.
Graphical representation of audience ratings based on critics ratings by genre of film between 2000 and 2017:
As I divided my dataset into 3 parts of 6 genres of films, I get three graphics.
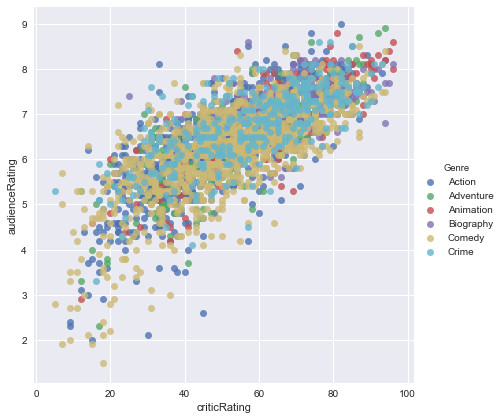
The public and critics share in most cases the same opinion on movies, especially for comedy or crime movies. Animation and adventure films are the most popular films by the public and critics.
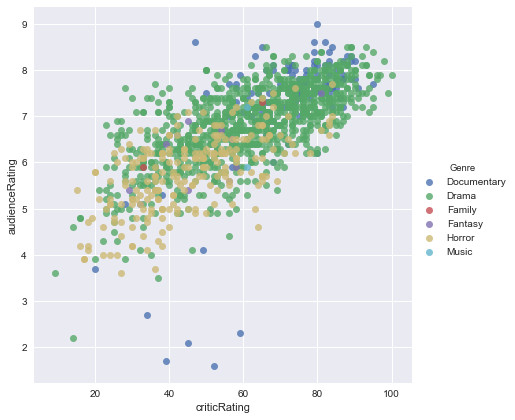
Drama and documentary films are the most appreciated by the public and critics.
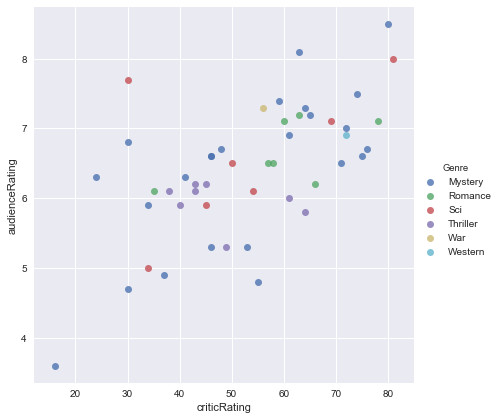
Mystery and science fiction movies are the most appreciated by the public and critics.
Boxplot of some data depending on the genres of movies between 2000 and 2017:
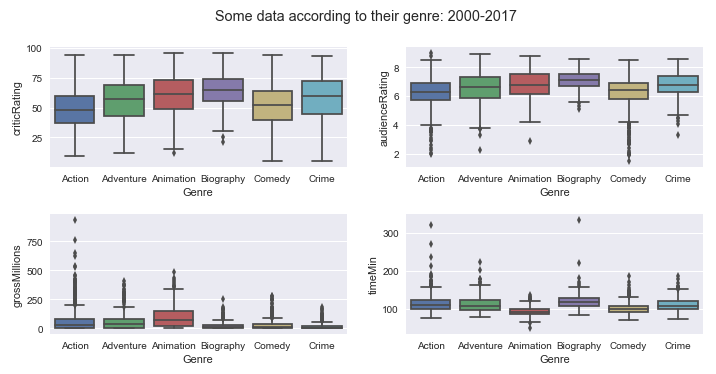
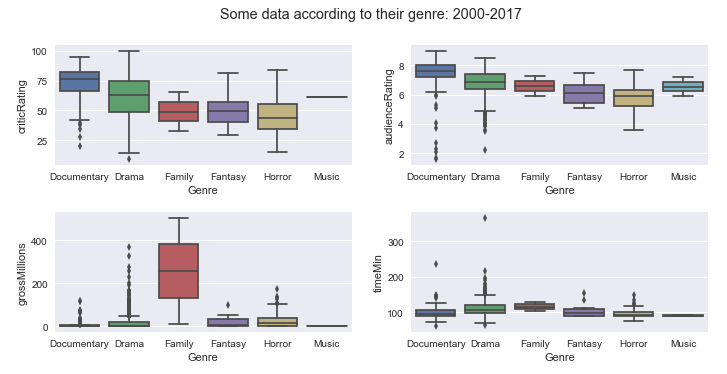
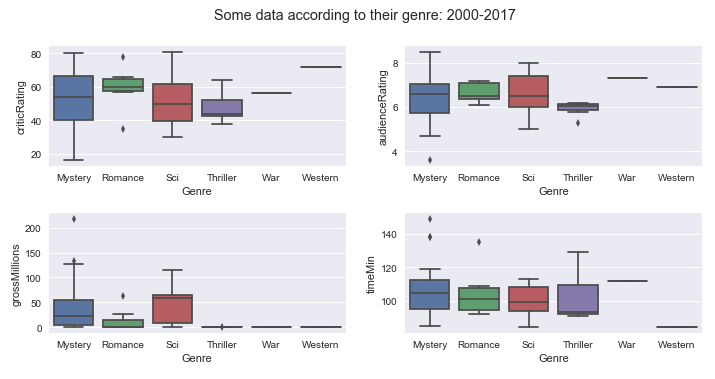
In these boxplots, one must refer to the median, at the minimum and maximum to have a view of the dispersion of the data around the median.
- Critics Ratings: Animation, biography, crime, drama, mystery and sci-fi are rated by critics.
- Audience Ratings: Animation, adventure, biography, crime, documentary, mystery and science-fiction are rated by the public the most.
- Gross for movies: Action, adventure, animation, family movies are the ones that have the most reported.
- Duration of movies: Action, adventure, biography, crime, family, drama and mystery movies are the ones that last the longest in terms of duration.
We can also draw these boxplots in the form of violin plot (violins) as below:
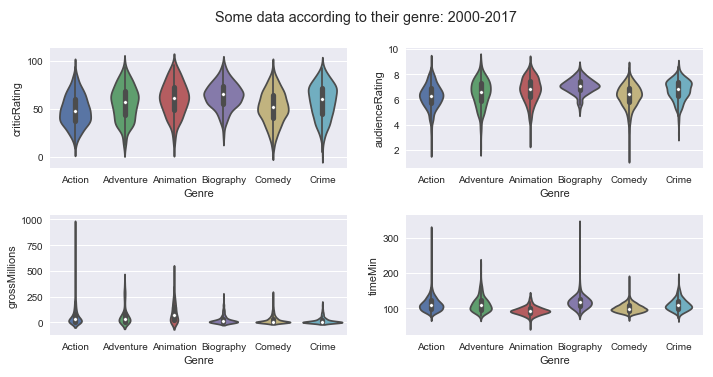
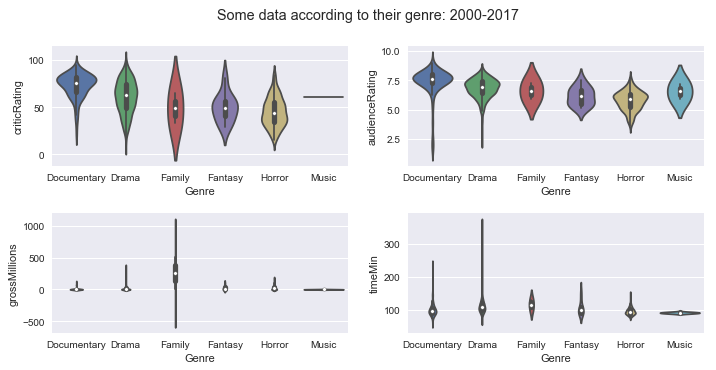
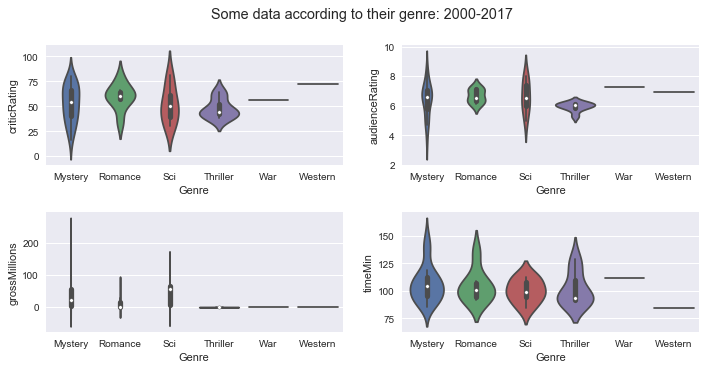
The interpretation of these charts is the same as those of boxplots.
With the Pandas library, I can also display graphs in grid form, which allows to display a large amount of information on the same graph.
I was able to display several information on the same graph which is:
- The audience rating on the y-axis
- The critics rating on the x-axis
- One genre per line
- One year per column
The dataset contains 18 years (2000 to 2017) and 18 genres, so there are many columns to display (18 columns) and genres to display. To improve visibility, I therefore divided in 6 years (2000 to 2005, 2006 to 2011 and 2012 to 2017).
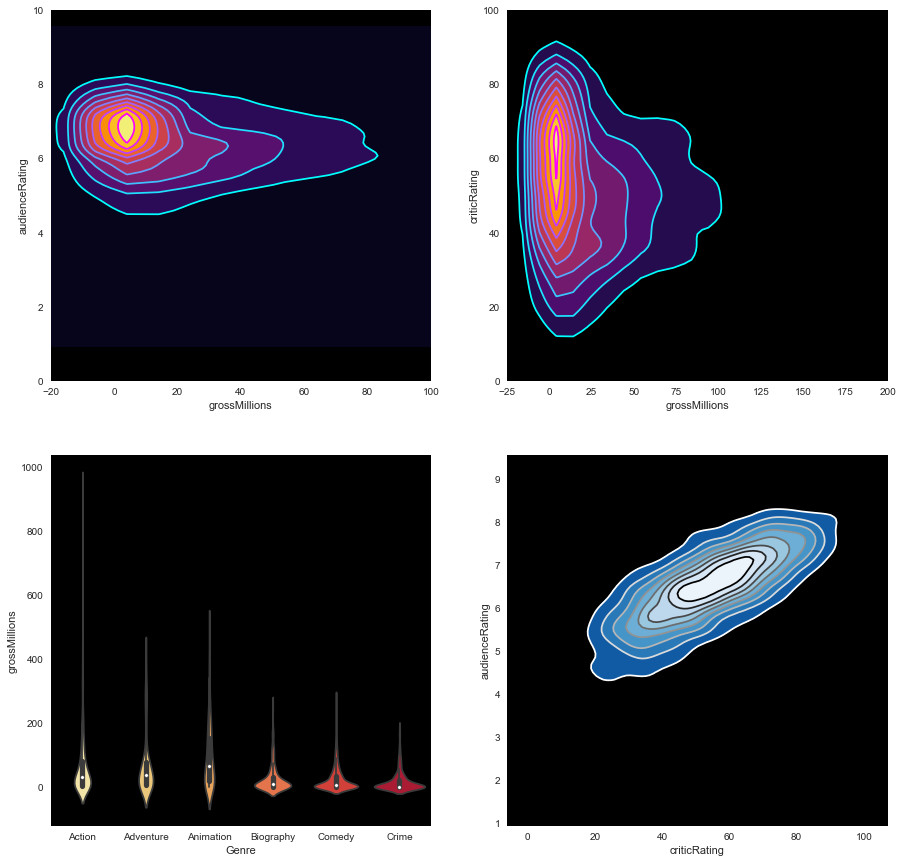
Graphical representation of audience ratings based on critics ratings from 2000 to 2005 for Action, Adventure, Animation, Biography, Comedy and Crime:

Graphic representation of audience ratings based on critics ratings from 2000 to 2005 for Documentary, Drama, Family, Fantasy, Horror and Music:
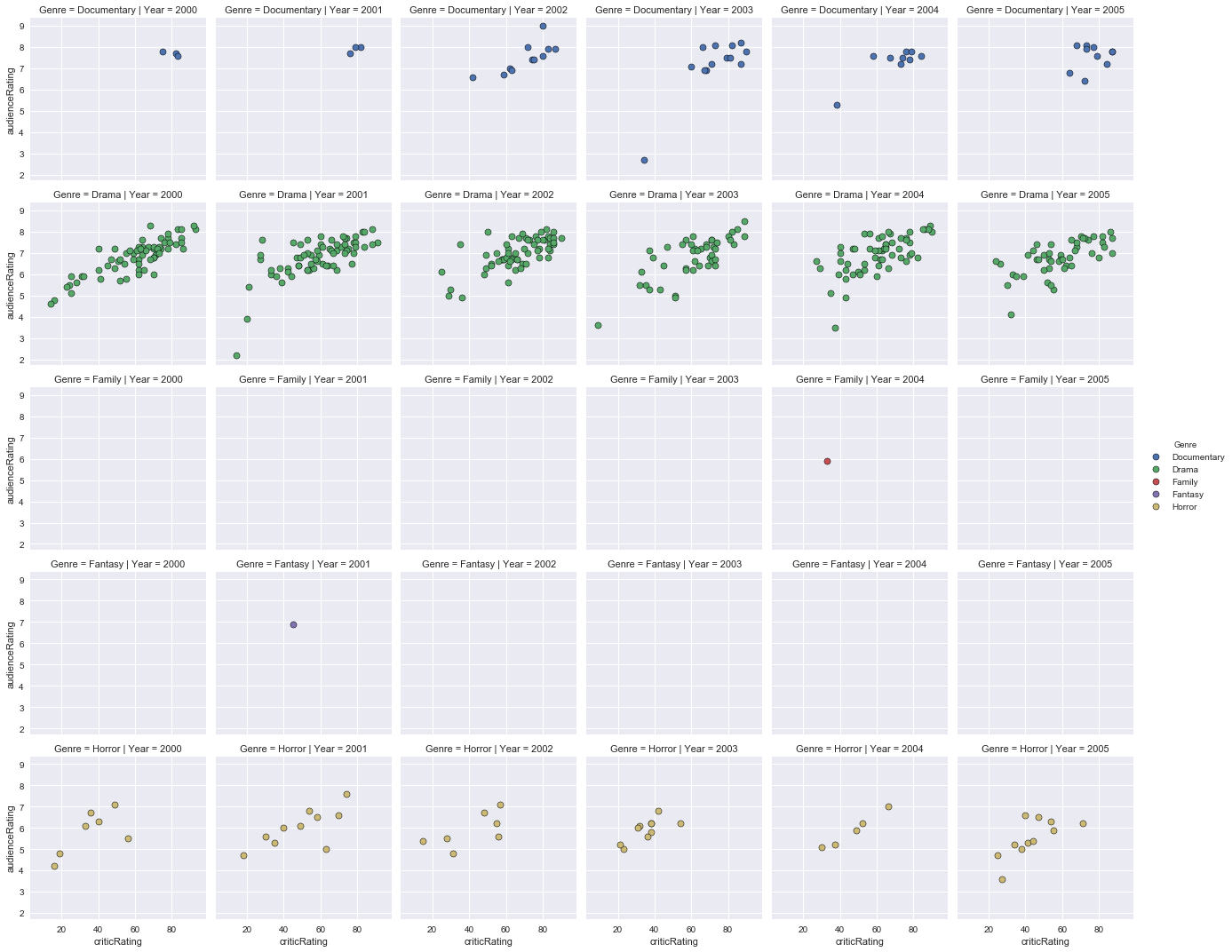
Graphical representation of audience ratings based on critics ratings from 2000 to 2005 for Mystery, Romance, Science Fiction, Thriller, War and Western films:

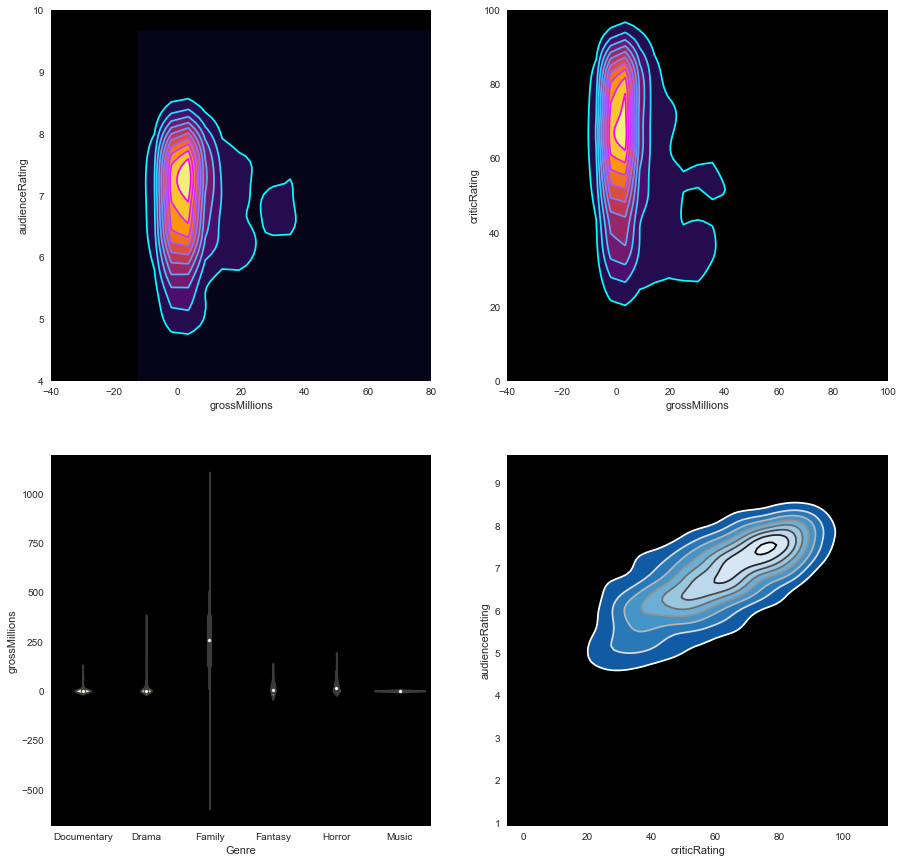
Graphical representation of the audience ratings according to the critics ratings from 2006 to 2011 for Action, Adventure, Animation, Biography, Comedy and Crime movies:

Graphical representation of the audience ratings based on critics ratings from 2006 to 2011 for Documentary, Drama, Family, Fantasy, Horror and Music movies:
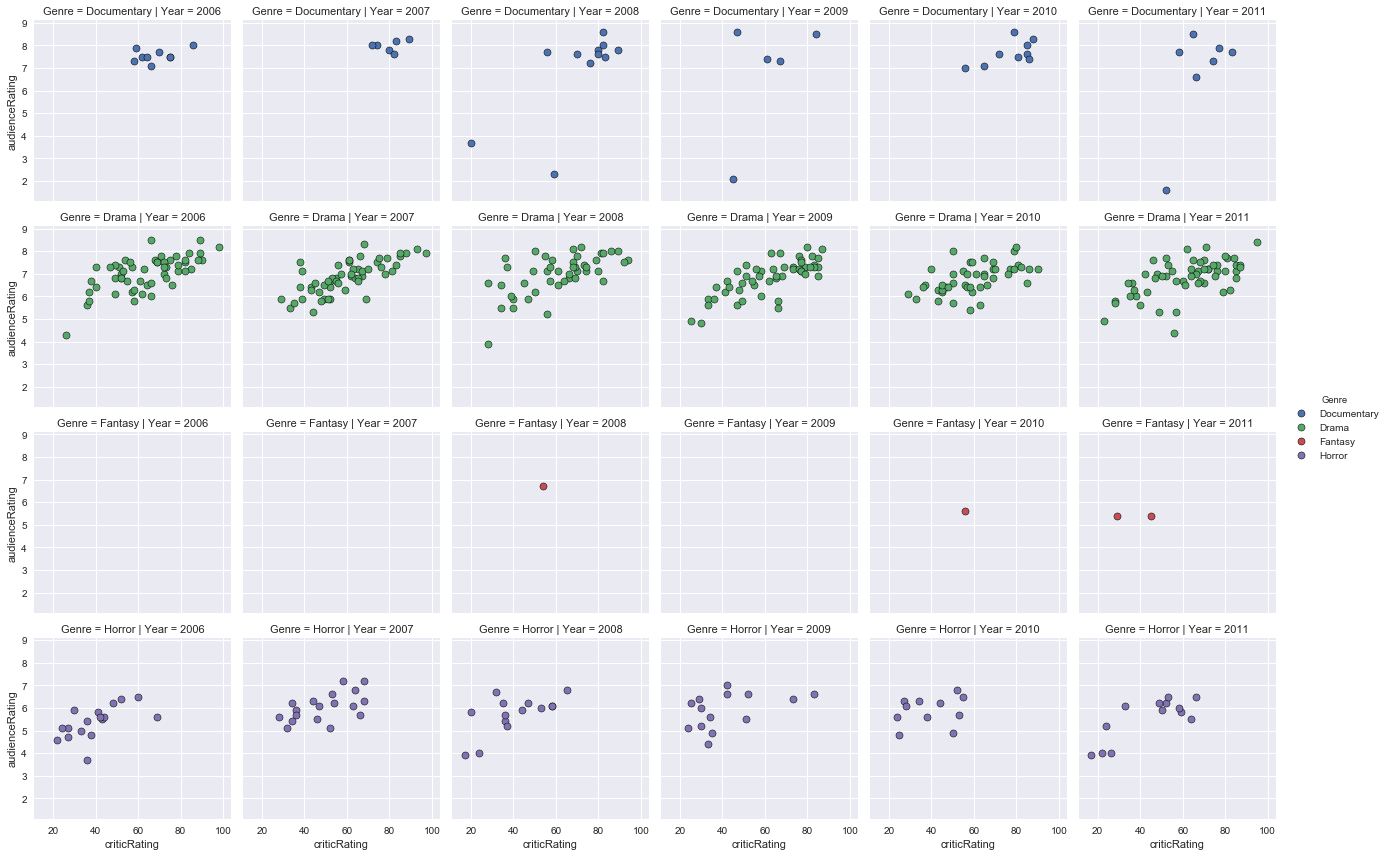
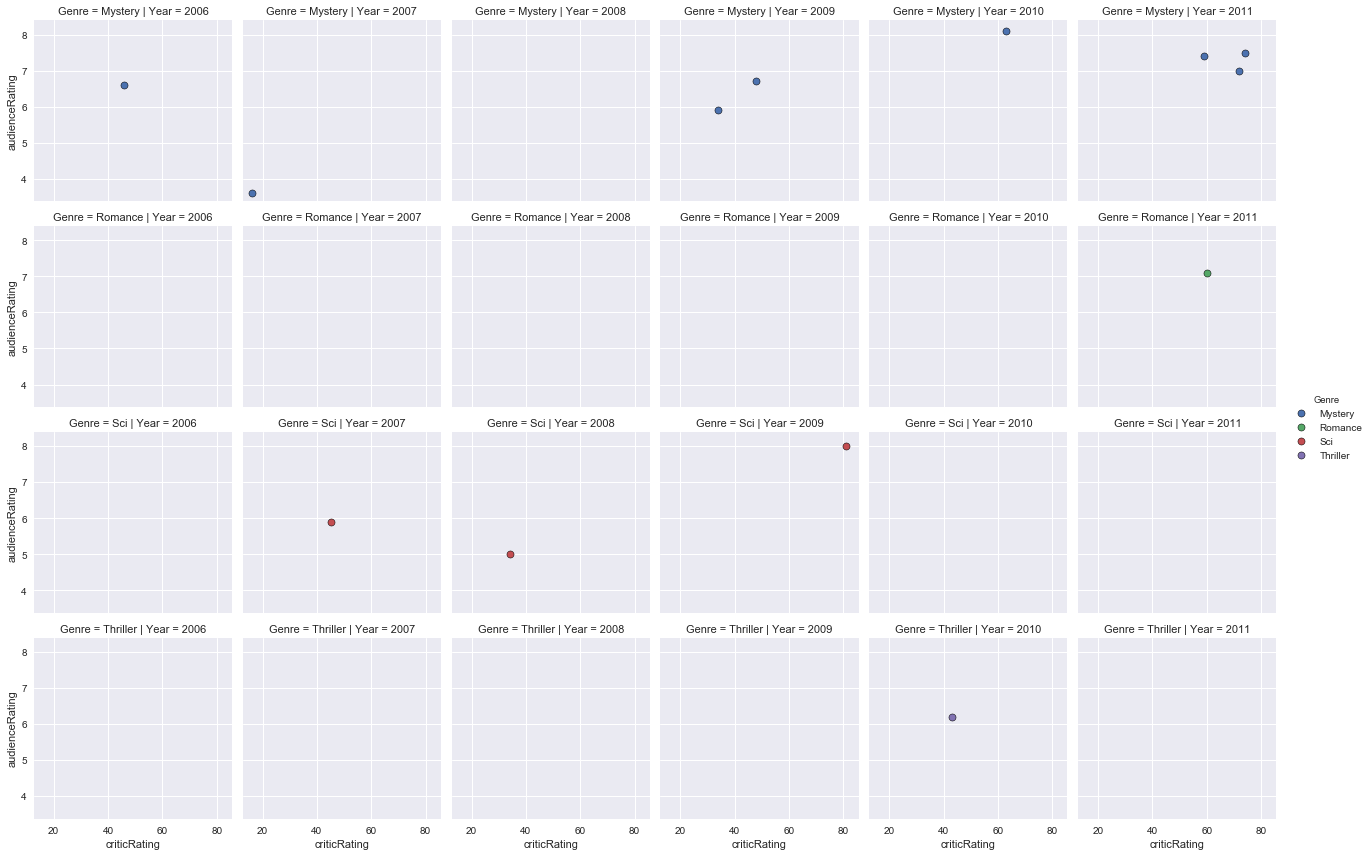
Graphical representation of audience ratings based on critics ratings from 2006 to 2011 for Mystery, Romance, Science Fiction, Thriller, War and Western movies:
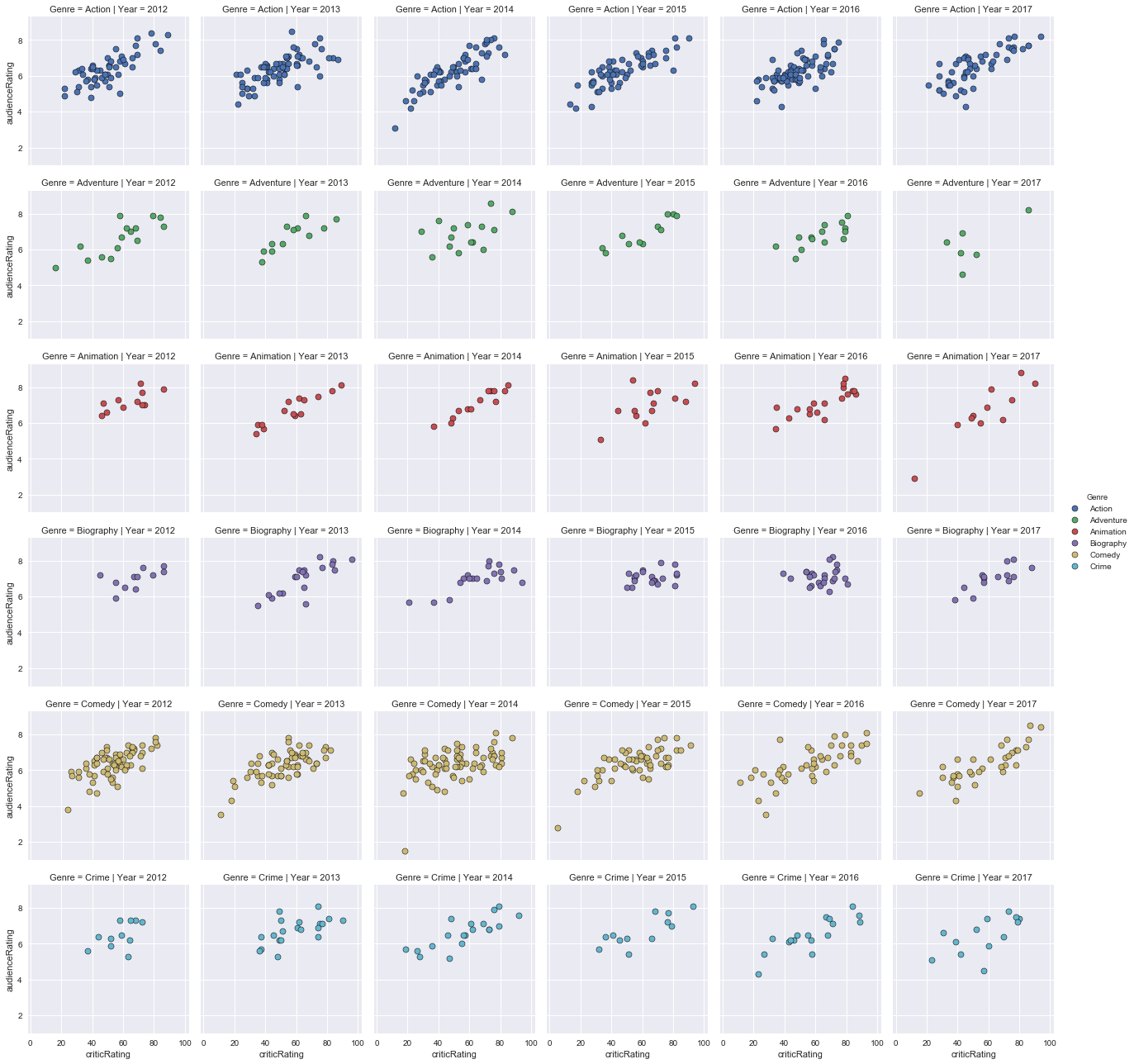
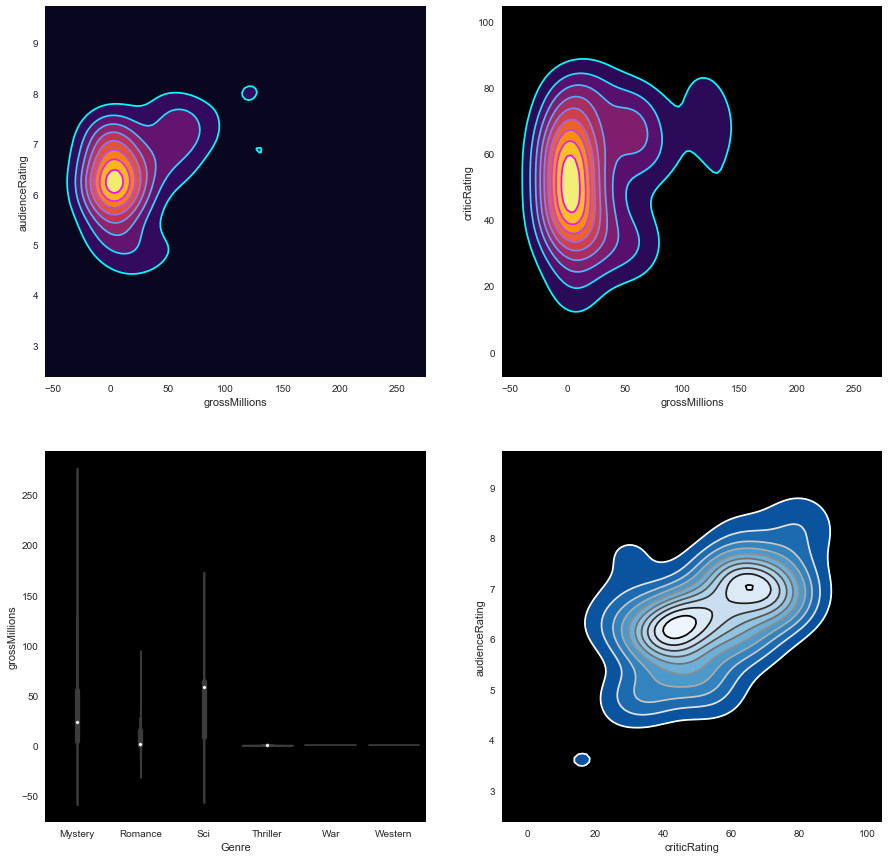
Graphical representation of the audience’s ratings according to the ratings of the critics from 2012 to 2017 for Action, Adventure, Animation, Biography, Comedy and Crime movies:
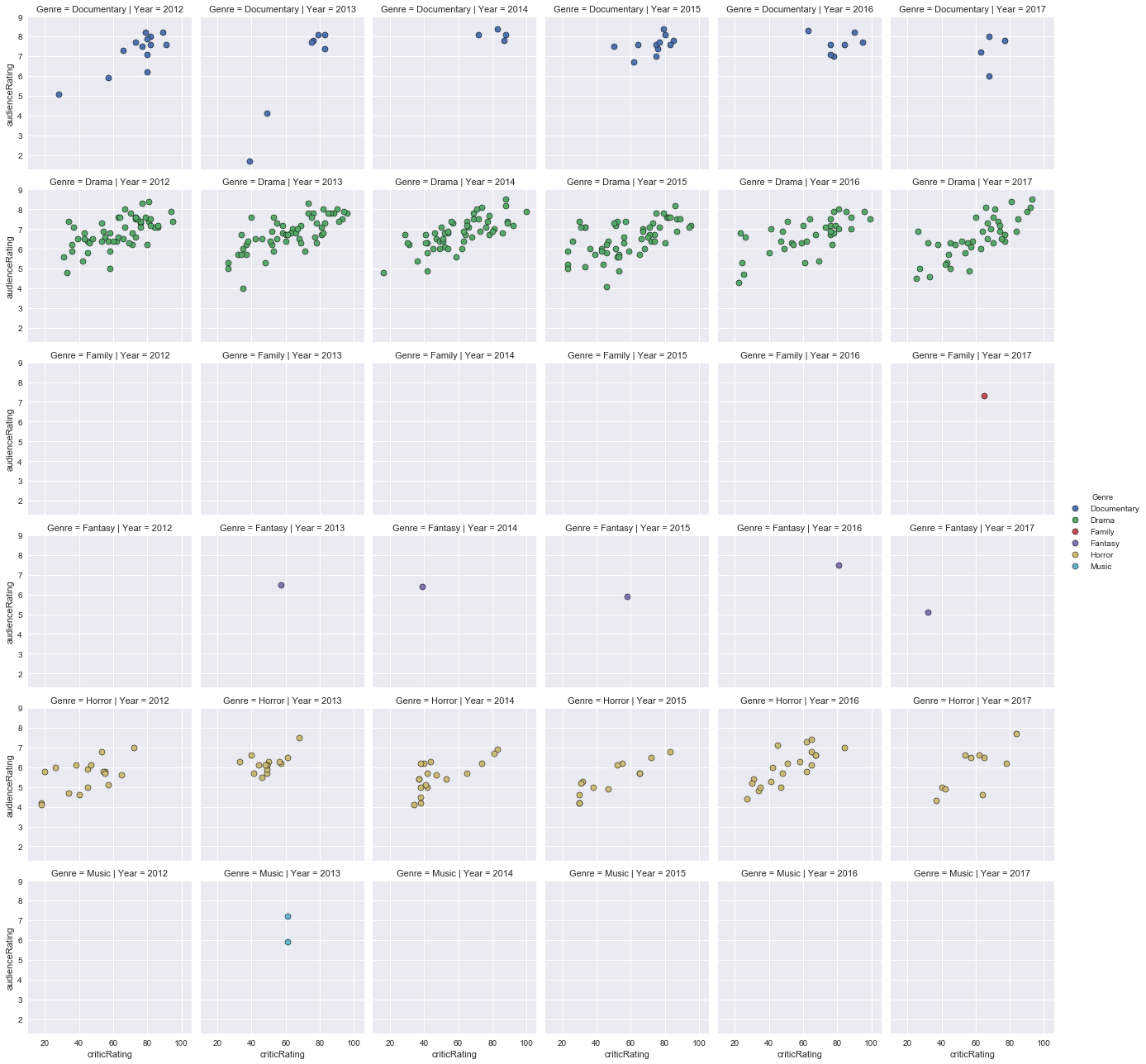
Graphical representation of audience ratings based on review ratings between 2012 to 2017 for Documentary, Drama, Family, Fantasy, Horror and Music movies:
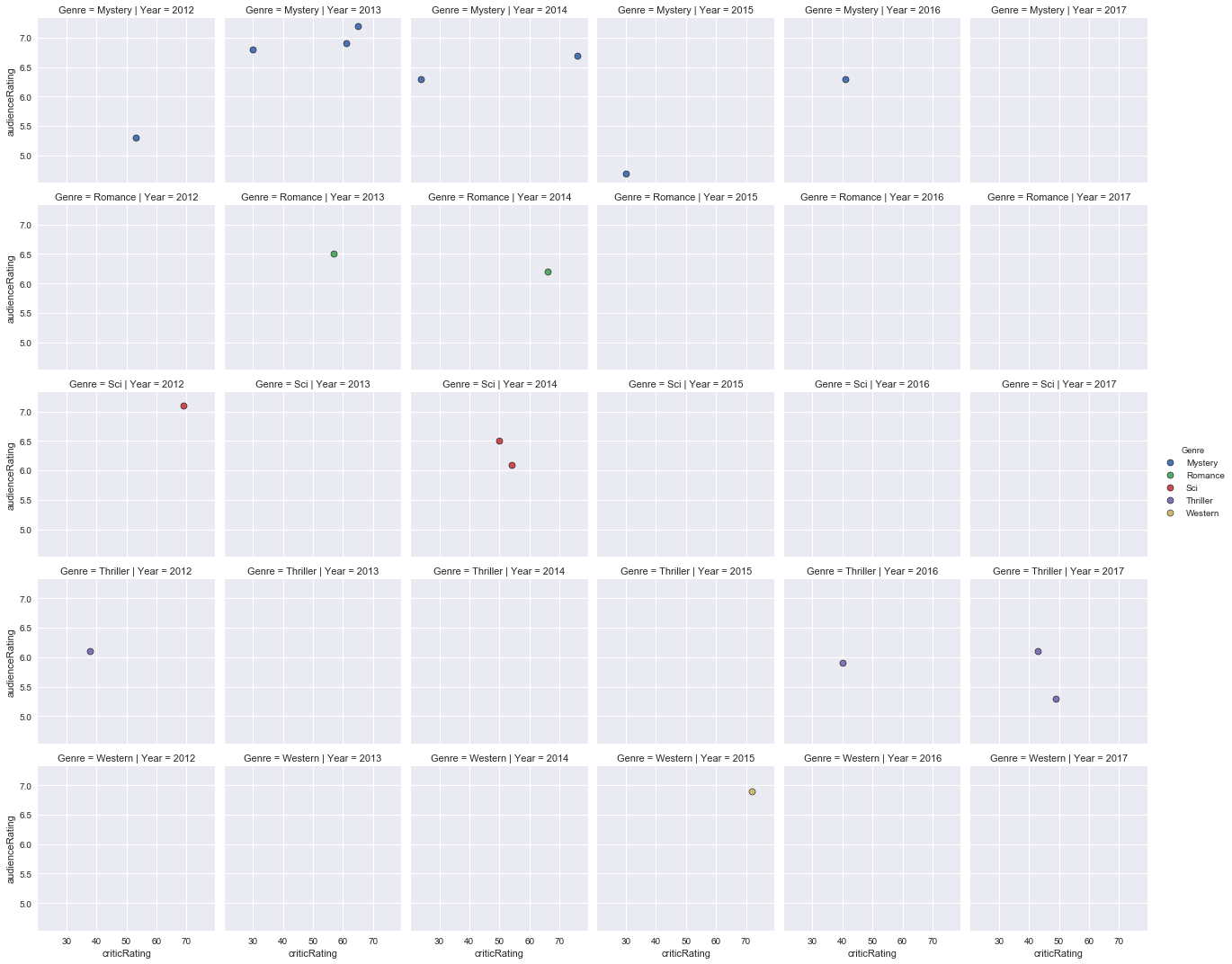
Graphical representation of audience ratings based on review ratings from 2012 to 2017 for Mystery, Romance, Science-Fiction, Thriller, War, and Western movies:
Interpretation of these results
- Between 2000 and 2005, there were very few family movies, fantasy, mystery, romance, science fiction, thriller and war, and even less for musical and western genre films between 2000 and 2005. The ratings of the public and critics are consistent.
- Between 2006 and 2011, very few fantasy movies, mystery, romance, science fiction and thriller and almost no family, musical, war and western movies. The public and the critics seem to be of the same opinion on most of the movies.
- Between 2012 and 2017, there were few family films, fantasy, mystery, romance, science-fiction, thriller, western and almost no war movie. The ratings of the audience and critics are quite similar.
Therefore, between 2000 and 2017, the public gives scores close to the ratings of the critics on a large majority of the films and one deduces that the public and the critics have the same opinion on a movie.
Dashboard
I drew 3 dashboards and each dashboards groups:
- Audience ratings based on movie recipes
- Ratings of the critics according to the movies gross
- Movies gross according to their genre
- Audience ratings based on critical ratings
The first dashboard is for Action, Adventure, Animation, Biography, Comedy and Crime movies from 2000 to 2017.
The second dashboard is for genre movies Documentary, Drama, Family, Fantasy, Horror and Music between 2000 and 2017.
The third dashboard is for genre movies Mystery, Romance, Science Fiction, Thriller, War and Western between 2000 to 2017.
The 3 dashboards show that the action, adventure, animation, and family films are the ones that reported the most, the audience ratings of the movies are quite close to those of the critics ratings, and the films that are well rated by the public and the critics are the ones who brought in a lot of money.
Conclusion
The preparation of the data, the modeling of these data, then the visualization of these data with a wide variety of graphs, and finally the interpretation of these graphs made it possible to conduct an analysis and a global view of movies released in the cinema between 2000 and 2017.
This study through a large volume of data, allowed me to determine the following points for movies between 2000 and 2017:
- Audience ratings of the movies are quite close to those of the critics ratings
- Critics rate more severely than the public
- Most movies last between 60 minutes and 120 minutes
- Movies that are well rated by public and critics make the most money
- The more the public appreciates a film, the more they vote and give a good rating
- Movies between 60 minutes and 150 minutes (2h30) make the most money
- Movies that exceed 3 hours bring in the least money
- Animation, biography, crime, drama, mystery and sci-fi movies are the highest rated by critics
- Animation, adventure, biography, crime, documentary, mystery and science-fiction movies are the highest rated by the public
- Action, adventure, animation and family movies are the ones that made the most money
- Action, adventure, biography, crime, family, drama and mystery movies are the ones that last the longest in terms of duration
- Biography, comedy, crime, drama and horror movies were the most numerous
- There were few mystery, western or war movies
- Movies that made the most money are action, drama and mystery movies



Be the first to comment